
과기부에서 주최하고 한국인터넷진흥원에서 주관하는 '2021 사이버보안 경진대회' 침해사고 Threat Hunting 부분에서 최우수상이라는 좋은 결과를 얻게 되어 간단히 리뷰해보고자 한다.
사실 이 대회에 참여한 계기는 작년에 좋은 결과를 얻었던 K-사이버 시큐리티 챌린지와 얼추 비슷한 흐름으로 가지 않을까 해서였다. 아쉽게도 작년 대회와는 많이 달랐다. (작년 대회 내용이 궁금하다면 이 링크를 참고)
이번 대회의 과제는 침해사고 데이터로부터 이상행위를 탐지하고, 공격자의 특성 및 침해사고의 흐름을 분석하여 대응방안을 제시하는 것이다.
그리고 제공되는 데이터셋은 SIEM 장비의 19만건 이벤트이고 해당 데이터에서 탐지된 각 공격 로그는 MITRE ATT&CK v7에 매핑되는 공격 기법으로 라벨링 하여 제시해야 한다.
먼저 전체적인 과정 설명에 앞서 우리 팀의 분석 방법론을 요약하여 소개하자면 다음과 같다.
① 데이터 전처리 및 ELK를 활용한 데이터의 시각화를 통한 의심 데이터 1차 분류
② ATT&CK TTPs 정보 및 이벤트 벡터 값의 비교 분석을 통한 공격 데이터 2차 분류
③ 분류된 데이터 간 상관관계 분석을 통한 공격 이벤트 3차 분류
① 데이터 전처리 및 ELK를 활용한 데이터의 시각화를 통한 의심 데이터 1차 분류
SQL 쿼리나 스크립트 등을 통해서도 데이터를 처리할 수 있으나 그 양이 워낙 방대하여 데이터를 탐색하고 분류하는데 한계점이 있다고 판단하여 빅데이터 분석 플랫폼인 ELK를 선택하였다.
ELK가 무엇이고 어떻게 사용하는가에 대한 내용은 이 리뷰에 있어 중요한 부분도 아니고 워낙 유명한 플랫폼이기에 설명은 생략하도록 하고 우리 팀이 구성한 Dashboard와 플랫폼 선택 이점에 대해서만 간단히 짚고 넘어간다.
실제 현업에서 쌓이는 데이터는 이보다 훨씬 방대하겠지만 대회에서 주어진 약 19만 건의 데이터들을 스크립트나 쿼리만으로 처리한다는 것은 매우 비효율적이다.
ELK를 빅데이터 분석 플랫폼으로 선택하는 가장 큰 이유는 역시 데이터 시각화의 측면에 있지 않나 싶다. 특히 이런 침해사고 데이터 분석에 있어 시각화는 매우 중요한 요소라고 생각한다. (과정 자체의 효율성이 달라진다)
예를 들어 침해사고 이벤트들은 주로 특정 시간대에 평소와는 다른 이벤트들이 다량 발생하는 특징을 지닌다. 공격 과정이 길어질수록 Anti-Virus 프로그램에 의해 식별될 가능성이 커 특정 시간 내에 처리하는 것이 유리하기 때문이다.
ELK를 활용하여 데이터를 시각화해놓으면 이런 부분들을 눈으로 쉽게 캐치해 낼 수 있다. 이를 위해 우리가 선택한 주요 섹터는 Cmdline, Timeline, Event_id, Pid, Host 5가지이다.
다른 벡터를 모두 보지 않더라도 이 5가지를 통해 구성한 Dashboard를 통해 공격은 아니더라도 일반적이지 않은 모든 의심 이벤트들에 대해선 1차 분류가 가능하였다.
② ATT&CK TTPs 정보 및 이벤트 벡터 값의 비교 분석을 통한 공격 데이터 2차 분류
이 과정은 MITRE ATT&CK의 공격 기법별 TTPs 정보와 빅데이터들의 이벤트 내 명령어, 사용 프로세스, 발생 시각 등 주요 벡터 값이 맵핑되는 공격 의심 이벤트들을 분류하는 과정이다.
여기서 MITRE ATT&CK에 대해 간단히 설명하면 어택(ATT&CK) 프레임워크는 마이터(MITRE)에서 실제 공격 사례 바탕인 킬 체인의 단계를 자체적으로 개발하여 정리한 것이다.
ㅇ 록히드 마틴의 사이버킬체인(Cyber Kill Chain) 모델
① 사전조사 및 취약 분석 - APT 공격 이전의 사전 준비 단계
② 악성코드 전파 - 악성코드를 취약한 시스템에 전달하는 단계
③ 시스템 침투 - 시스템 접근 권한을 획득하는 단계
④ 지휘 및 통제 - C&C채널을 구축하는 단계
⑤ 레터럴 무브먼트 - 네트워크와 주변 기기들을 감염시키는 단계
⑥ 공격 감행 - 사이버 공격 단계
사이버 공격은 대략적으로 위 6가지의 단계를 거치게 되는데 보안 담당자는 아래 단계에서 연결고리(Chain)를 끊어 피해를 최소화하는 것이 이 전략의 목표이다.
마이터 어택은 여기에서 더 나아가 지능화된 공격의 탐지를 향상하기 위해 위협 기술을 패턴화한 것인데, 해킹 공격에 대해 방법(Tactics), 기술(Techniques), 절차(Procedures) 등 TTPs 정보를 맵핑하여 공격자의 행위를 식별할 수 있는 프레임워크로 발전시켰다.
MITRE ATT&CK 홈페이지에는 위와 같이 공격 기술의 Tatic, Technique에 대해 그 단계별로 나열된 Matrices를 볼 수 있으며, 이를 선택하면 실제 공격에 사용된 세부 기술도 확인 가능하다.
설명을 위해 간단한 예를 들어보자 Tech.Num가 T1070인 Indicator Removal on Host는 멀웨어가 호스트 침입 과정에서 생성된 아티팩트를 삭제하거나 변경하는 데 사용하는 공격 전술이다.
T1070에서는 다양한 Technique 정보들이 있는데 여기서 중복되는 몇 가지 특징들을 추려보면 쉘 명령어가 발생하면서 event_id 값이 '1500'으로 찍히거나 'net.exe' 등의 프로세스를 사용하고, cmdline 벡터엔 'delete'가 담긴다.
이러한 정보들을 바탕으로 쿼리를 작성하고 데이터 내에서 해당 벡터를 지니는 이벤트를 분류하면 다음과 같은 이벤트를 추출할 수 있다. (예시로 하나만 추출)
이 이벤트가 실제 공격인지는 확정 지을 수 없다. 사용자가 직접 사용한 명령어이거나 정상적인 프로그램이 발생시킨 이벤트일 가능성도 배제할 수 없기 때문이다. 우리는 이 이벤트가 과연 실제 공격 과정에서 발생된 것이 맞는지 확인하기 위해 다음 과정을 진행하였다.
③ 분류된 데이터 간 상관관계 분석을 통한 공격 이벤트 3차 분류
앞선 과정을 통해 분류된 의심 이벤트들은 개별 데이터 간 자식-부모 프로세스 관계, 명령어 사용 및 응답 값, 이벤트 발생 시각 등 다양한 벡터들을 통해 그 상관성을 알아낼 수 있다.
우리 팀은 다양한 벡터들의 상관관계를 분석하여 그 관계가 높은 묶음을 그룹화시키는 과정을 진행하였고 이렇게 분류된 그룹의 전체 이벤트가 실제 공격에 사용되었는지에 대한 여부를 최종적으로 판단하였다.
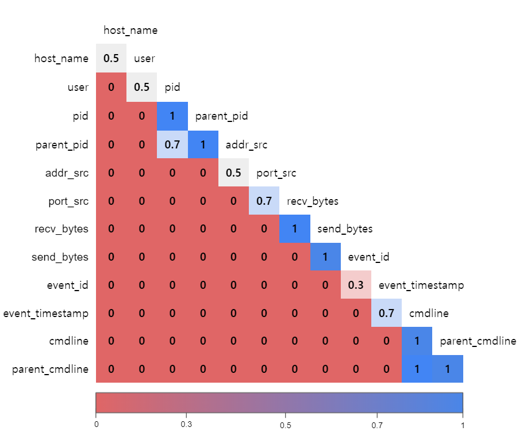
위 표를 간단히 설명하자면 가로축은 A 이벤트 벡터 값, 세로축은 B 이벤트의 벡터 값을 의미하고 상관계수는 0(관계성 낮음) ~ 1(관계성 높음)로 표현되었다.
예를 들어 pid와 parent_pid가 일치한다면 두 데이터는 단일 행위 그룹으로 묶일 여지가 높아 상관계수가 1로 메겨지며, event_id가 일치하는 경우 단일 행위 그룹으로 묶일 가능성도 존재하지만 반대의 가능성이 더 높기 때문에 0.3으로 메겨진다.
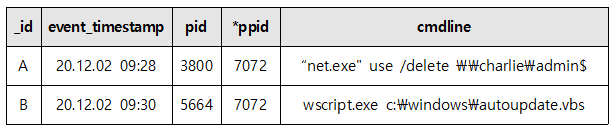
앞선 데이터 정적 분석 과정에서 분류되었던 의심 이벤트 A와 상관관계 분석 스크립트를 통해 추출된 이벤트 B는 일련의 행위 그룹으로 판단된다. 이벤트 발생 시간 대역(event_timestamp) 및 부모 프로세스(parent_pid) 그리고 PC 명(host_name) 동일하기 때문이다.
예시를 위해 두 이벤트 값을 가져왔지만 실제 추출된 결과를 보면 해당 그룹은 여러 아티팩트를 통해 공격 행위를 수행하였음을 명확히 분류할 수 있었다.
결과적으로 보면 우리 팀이 진행하였던 위와 같은 분석 방식은 단순히 벡터 비교 분석을 통해 개별 데이터를 일차원적으로 식별하는 것보다 상관관계가 높은 데이터들을 그룹화하여 다차원적인 분석을 진행함으로써 각 이벤트들의 동작 행위나 목적성을 더욱 명확하게 분석할 수 있었던 것 같다.
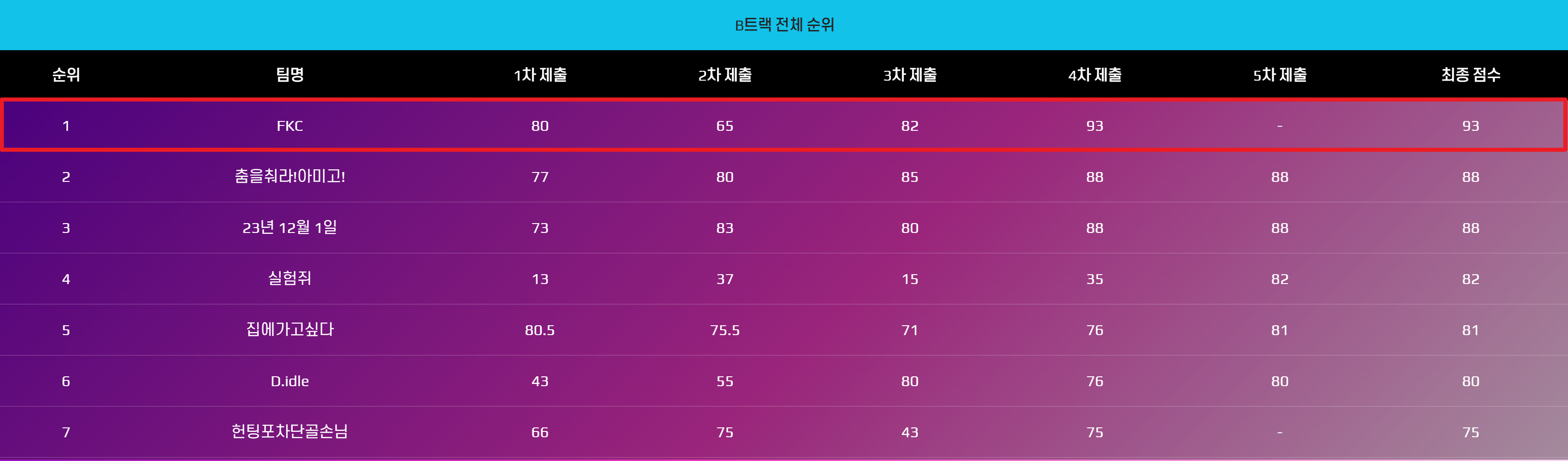
실제로도 예선 & 본선 가장 최상위의 탐지율을 기록하였다.
침해사고 개요도나 최종 분석 결과에 대한 내용은 데이터 공개 불가 방침이 있었어서 아쉽게도 블로그에 더 자세히 적지는 못할 것 같다. 대회 기간이 길고 대부분 평일에 진행되다 보니 회사 일정 때문에 다른 대회보다 2배는 힘들었던 것 같다. 그래도 결과가 좋아서 힘들었던 기억이 추억으로 남을 것 같아 다행이다..^^
'대회후기' 카테고리의 다른 글
| [대회] K-사이버 시큐리티 2020 대회 우승 (0) | 2021.11.01 |
|---|---|
| [대회] FIESTA 2020 금융보안 위협분석 대회 준우승 (0) | 2021.11.01 |


댓글