
과기부에서 주최하는 국내 최대 규모 사이버 보안 경연대회 'K-사이버 시큐리티 챌린지 2020'의 웹로그 이상행위 패턴 분석 대회에서 좋은 결과를 얻게 되어 이에 대한 리뷰를 간단히 적어보고자 한다.
대회 주제는 웹로그 빅데이터 분석을 통해 Web Scraping, Credential Stuffing 등의 공격행위를 식별하고 그 특징정보를 도출하여 패턴을 탐지, 식별할 수 있는 알고리즘을 제시하는 것이다.
제공받은 웹로그 데이터는 232MB, 약 150만 Row에 이르는 양인데 생각보다는 많지 않았다. (트랙 자체가 공격 행위를 얼마나 많이 맞추었나라기 보다 탐지 알고리즘의 참신성, 효율성 등을 평가하는 것이기 때문에 그런 것 같다.)
먼저 탐지 알고리즘을 도출해낸 과정을 크게 보면 다음과 같다.
① 전체 데이터 셋 내 개별 유저를 특정 지어 패킷을 묶음
② 대다수 유저와 상이한 패턴을 보이는 유저를 식별하고 유사도 점수가 높은 패킷을 묶음
③ 식별된 패킷을 집중 분석하여 공격 유형별 분류 및 1차 탐지 룰 설계
④ 분류된 패킷에 공격 유형별 번호(1~5번)를 부여하여 지도 학습에 필요한 답지 구축 및 기계학습 모델 설계
⑤ 1차 탐지 룰과 기계학습 간의 상이한 탐지 결과물을 분석하여 누락 탐지된 공격 시나리오(6번)를 감지
⑥ 새롭게 발견된 공격 시나리오(6번)를 감지할 수 있도록 1차 탐지 룰을 개선
⑦ 4~7번 과정을 반복하며 n차 탐지 룰 탐지 룰 및 n차 기계학습 모델을 생성하여 n번 개선된 최종 공격 탐지 룰 구축
① 전체 데이터 셋 내 개별 유저를 특정 지어 패킷을 묶음
위 과정을 거친 이유는 데이터셋 내에 존재하는 대부분의 공격행위들이 개별 패킷만 봐서는 공격 여부를 식별하기가 불가능하기 때문이다.
일례로 Credential Stuffing의 경우 개별 패킷은 단순 로그인 시도로 보일 수 있으나 패킷 출발지(Host IP)와 사용 기기(User Agent)를 통해 분류된 유저별 패킷 묶음을 봤을 때 그 시도가 수 천 회에 이른다면 공격으로 식별이 가능하기 때문이다.
(사실 User Agent까지 포함해 분류하는 것에 대해서는 각각의 장단점이 있어 좀 고민을 했지만 다중 이용 시설과 같은 출발지의 포함 여부를 알 수 없어 포함하기로 하였다.)
② 대다수 유저와 상이한 패턴을 보이는 유저를 식별하고 유사도 점수가 높은 패킷을 묶음
패킷은 필드별로 각각의 의미를 지니고 있고 이 필드 사이에서 이상행위를 찾기 위한 유의미한 Feature를 찾아내고자 분석하였다.
그중에서 대표적으로 'Timestamp'와 'Status Code' 정보로부터 추출한 두 가지 Feature에 대해 설명하고자 한다.
위 그림을 보면 세로축은 유저별 1초에 보낸 패킷 수의 표준 편차를 의미하고, 가로축은 유저별 1초에 보낸 초당 패킷 평균 개수를 의미한다.
그림에 보이는 녹색은 패킷 유입량이 적고 유입 속도 또한 고른 그룹을 의미하며, 적색은 패킷 유입량이 많고 유입 속도 또한 고르지 못한 그룹을 나타낸다.
사람이 1초에 보낼 수 있는 패킷의 수와 표준편차 수치는 제한적일 수밖에 없기 때문에 이는 유의미한 Feature로 활용될 수 있는 것이다.
두 번째 그림은 세로축은 패킷의 개수(log scale 값), 가로축은 Status Code의 종류를 의미한다.
패킷 내 정상 응답 값을 나타내는 200 코드가 압도적으로 많은 비율을 차지하는 유저들이 대부분이었으나, 일부 유저의 경우 공격 행위별로 Status Code의 비율이 달라지는 특징을 보였다.
예를 들어 'Web Scaaning' 공격의 경우 페이지 Not Found를 뜻하는 404 코드의 비율이 급격히 상승하였고, 'Credential Stuffing'의 경우 똑같은 Path에 대한 요청이 과도한 특성으로 인해 Client Closed Request를 뜻하는 499 코드의 비율이 높아졌다.
위와 같은 이유로 Status Code 비율 역시 Feature로 활용할 수 있었다.

이러한 방식으로 의미 있다고 판단되는 Feature들을 추려낸 결과 아래 총 28개의 Feature를 발견할 수 있었다.
③ 식별된 패킷을 집중 분석하여 공격 유형별 분류 및 1차 탐지 룰 설계
이렇게 찾아낸 28개의 Feature를 활용하여 전체 패킷을 공격 유형을 식별하고 분류해주는 Python 코드를 작성하여 1차 정답 데이터를 추출하였다. 대략적인 코드 Flow는 아래와 같다.
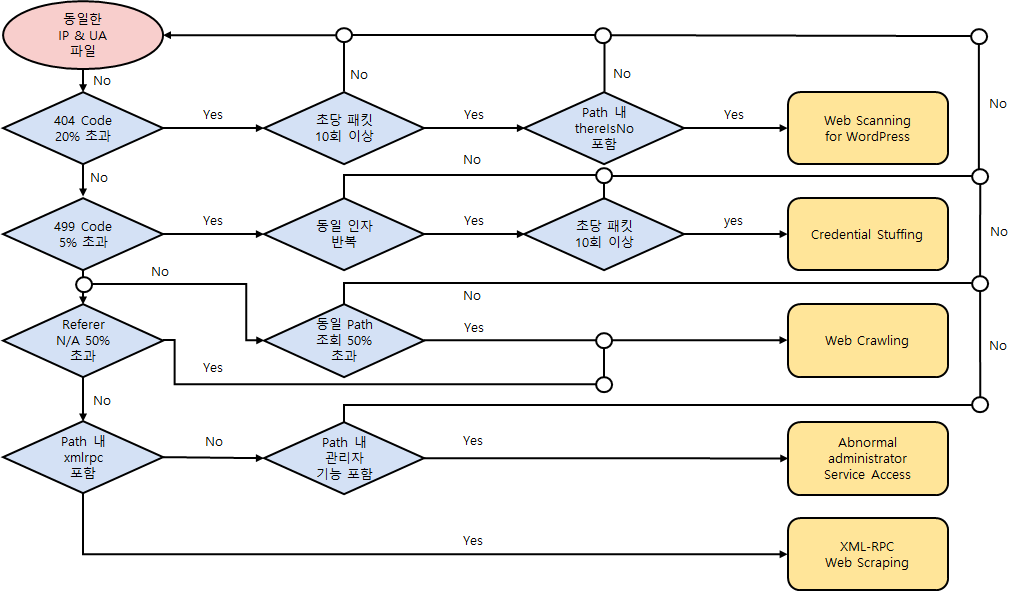
* IP = Host IP / UA = User Agent / Code = Status Code / 인자 = 파라미터 중 정적 변수
'Web Scanning' 같은 경우는 Not Found 코드 비율, 비정상적 접근 횟수, Dirbuster 툴을 사용한 흔적 등의 Feature를 활용하였다.
'Credential Stuffing'은 Client Closed Request 코드 비율, ID & PW와 같은 동일 인자의 반복, 비정상적 접근 횟수 Feature를 활용하였다.
'Web Crawling'은 Referer가 존재하지 않는 패킷의 비율, 동일 Path에 과도하게 접근한 비율 등의 Feature를 활용하였다.
'Abnormal Administrator Service Access' 비정상적 관리자 서비스 접근의 경우는 Path 내 관리자 권한의 세션 체결을 거치지 않은 채 관리자 페이지에 대한 접근이 비율이 높은 Feature를 활용하였다.
마지막으로 'XML-RPC Web Scraping' 같은 경우는 XML-RPC 프로토콜이 포함되고 'Web Crawling'과 동일한 Feature를 사용해 공격을 식별하였다.
④ 분류된 패킷에 공격 유형별 번호(1~5번)를 부여하여 지도 학습에 필요한 답지 구축 및 기계학습 모델 설계
이렇게 분류된 정답 데이터들은 탐지 룰의 정확성 향상을 위해 인공지능 모델을 통해 검증하는 과정을 거치게 된다.
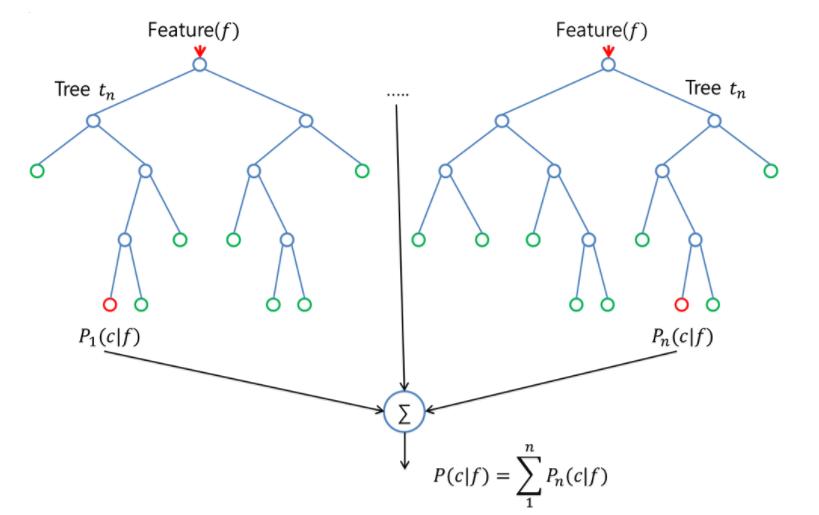
인공지능 모델은 2가지를 사용하였는데 그중 먼저 'Random Forest'는 하위 샘플과 예측 변수를 사용하여 만들어진 많은 수의 의사 결정 나무(Decision Tree)에 대한 앙상블을 통해 평균적으로 예측된 수준을 얻는 방법론이다.
앞선 데이터 탐색을 통해 찾아낸 Feature들과 이상행위로 식별한 패킷을 활용해서 수 백, 수 천 개에 이르는 의사 결정 나무들을 만들고 이를 통해 최종 예측 결과를 산출하였다.
(현업에서도 가장 많이 사용되는 알고리즘 중 하나로 분류 분석에 있어 성능이 우수하기 때문에 해당 알고리즘을 활용하였다.)
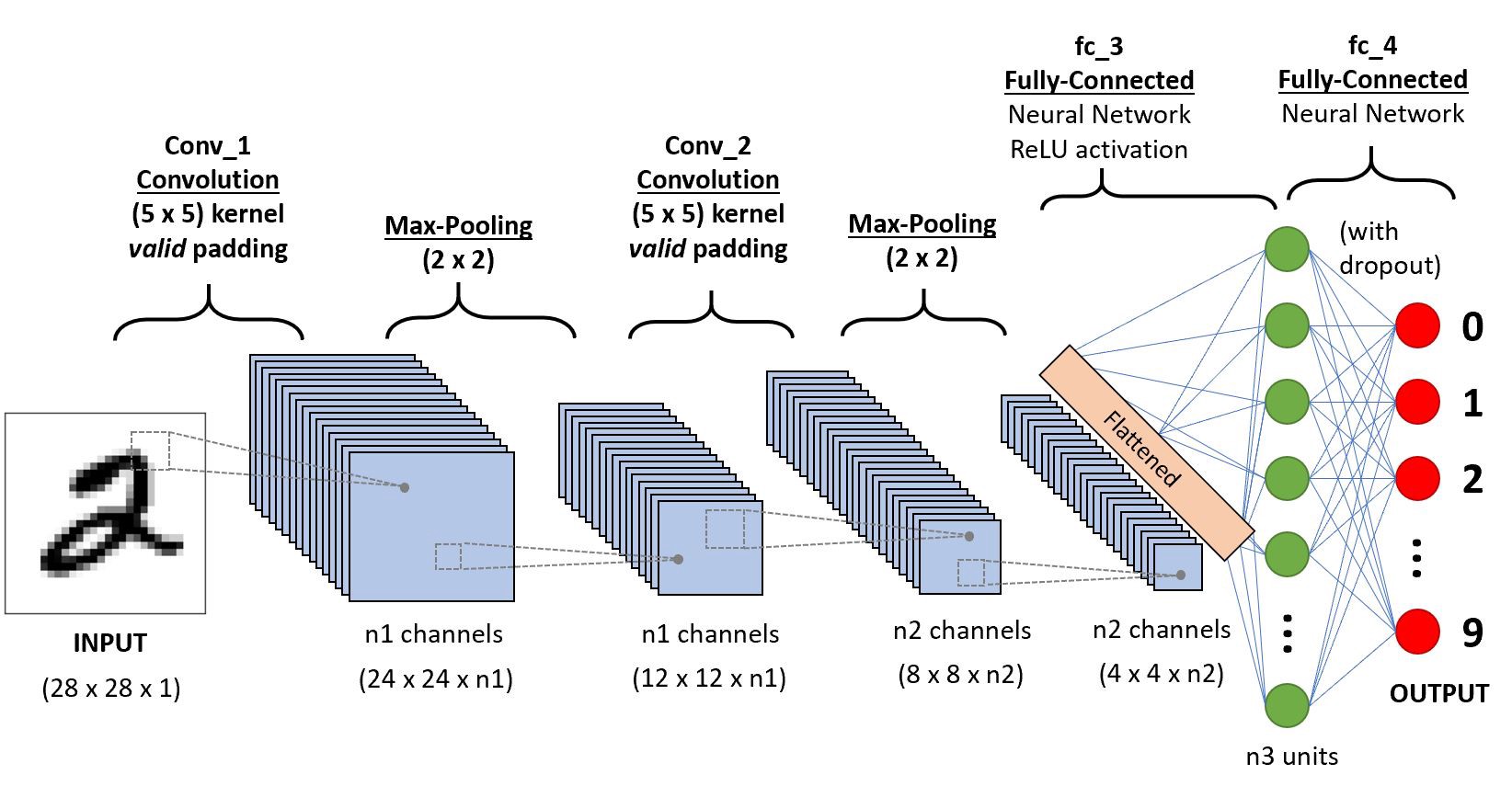
두 번째로 사용한 알고리즘은 'Convolutional Neural Network'이다. 데이터들 간의 상관관계를 분석해서 원하는 예측 값을 도출해주는데 최적화된 알고리즘으로 유저별 공격 여부 및 어떤 종류의 공격을 했는지 그 예측 값을 도출해내기 위해 사용하였다.
(전체 데이터가 크지 않기 때문에 학습 데이터 양이 많지 않아 'Recurrent Neural Network' 보다 학습에 용이한 이점이 있다.)
그리고 이 두 알고리즘의 최종 F1-Score를 통해 탐지 룰 모델과 인공지능 모델을 통해 얻은 정답 데이터 간 차이점이 있다는 것을 발견하였고 이 차이점을 보이는 데이터 대한 상세한 분석을 진행하였다.
⑤ 1차 탐지 룰과 기계학습 간의 상이한 탐지 결과물을 분석하여 누락 탐지된 공격 시나리오(6번)를 감지
그 차이점은 Page Redirect를 뜻하는 301 코드의 비율 Feature에서 발견되었다.
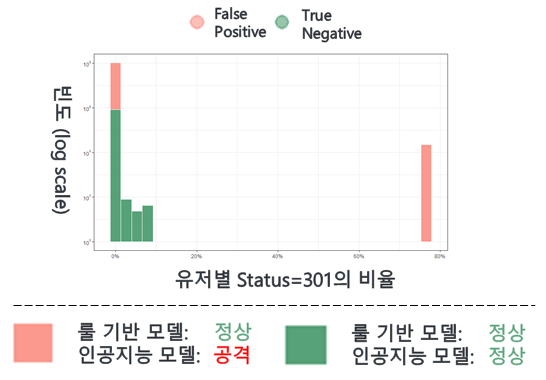
그림을 보면 녹색은 룰 기반과 인공지능 모델에서 모두 정상이라 판별한 것이고, 적색은 룰에서는 정상으로 판별하였으나 인공지능 모델에서 공격이라 판단한 패킷을 나타낸다.
이때, 이 적색에 해당하는 패킷을 분석해본 결과 기존에 발견하지 못한 'Web Scanning' 공격 데이터임을 알 수 있었다.
해당 데이터를 식별해내지 못했던 이유를 살펴보면 기존 'Web Scanning' 식별과 관련된 플로우에 답이 있다.

'Web Scanning'에 성공하여 페이지를 찾았을 때 정상 응답을 의미하는 200 코드가 반환되고 실패했을 때는 Not Found 404 코드가 응답으로 반환될 것이라 추측하였기 때문이다.
실제로는 웹 서버 설정에 따라 'Web Scanning'에 실패했을 때 404 코드뿐 아니라 Page Redirec에 해당하는 301 코드가 반환되는 사례도 빈번히 발생한다.
따라서 우리가 작성한 코드는 이 301 코드 비율이 높았던 비정상 유저에 대해 누락 탐지를 한 것이다.
⑥ 새롭게 발견된 공격 시나리오(6번)를 감지할 수 있도록 1차 탐지 룰을 개선
위 과정을 통해 찾아낸 누락 탐지 데이터를 다시 지도 학습을 위한 정답 데이터로 포함시키고 인공지능 모델로 학습에 활용을 시켜 새로운 탐지 룰을 개선한다.
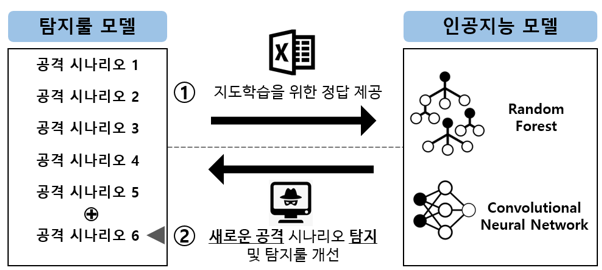
⑦ 4~7번 과정을 반복하며 n차 탐지룰 및 n차 기계학습 모델을 생성하여 n번 개선된 최종 공격 탐지룰 구축
그리고 이러한 과정을 n차 반복하여 두 모델 간의 결과가 어느 정도 동일함을 보일 때 이를 최적의 알고리즘으로 판단하여 탐지에 활용하게 되는 것이다.
인공지능 모델을 중첩 활용한 탐지 룰을 현업에 적용시키기에 앞으로 많은 부분을 보완해 나가야겠지만 이를 잘 개선시킨다면 단순히 보안 담당자 개개인의 역량 수준에 영향을 받는 탐지 룰 보다 높은 정확도와 효율성을 보장할 수 있을 것이라 생각한다.
주로 CTF 대회만 나가다가 이런 대회를 참여해보니 어떻게 해야 하나 막막하고 어려웠다. 특히 다들 회사나 학업과 병행하다 보니 저녁 시간과 주말을 포기하게 되었는데 이점이 가장 힘들었던 것 같다.
그래도 엄청난 실력을 가진 우리 팀원들 덕분에 좋은 결과를 얻을 수 있었어서 너무 고맙다는 말을 전한다^^
'대회후기' 카테고리의 다른 글
| [대회] 사이버보안 침해사고 Threat Hunting 대회 최우수상 (0) | 2021.12.18 |
|---|---|
| [대회] FIESTA 2020 금융보안 위협분석 대회 준우승 (0) | 2021.11.01 |


댓글